
The inability to share private health data can severely stifle research and innovation in health informatics. Studies based on unpublished electronic medical record (EMR) data cannot be reproduced, thus future researchers are not able to use them to develop and compare new research. This contributes to the reproduciblity crisis in biomedical research. Making open data available for research can spur innovation and research. The public Medical Information Mart for Intensive Care datasets, MIMIC-II and MIMIC-III, are widely used with over 2000 citations reported in Google Scholar in March 2020. But since MIMIC-II and MIMIC-III focus on Intensive Care Unit patients in Boston hospitals, the resulting research may be biased and have limited generalization. The cost and time required, along with re-identification risk concerns make de-identification only a partial solution to this problem.
Recent synthetic data generation methods provide an attractive alternative for making data available for research and education purposes without violating privacy. Deep learning approaches for synthetic data specifically show significant promise. In the future, synthetic data generation methods combined with automatic machine learning methods could enable synthetic versions of data to be released when research papers are published. Results could be reproduced and novel methods and analysis could be developed without compromising patient privacy. To accomplish this, synthetic data assets must have
- Privacy: how well does the synthetic generation data method preserve anonymity;
- Resemblance: whether the distribution of synthetic data is indistinguishable from the distribution of real data;
- Utility: can research studies be reproduced successfully with synthetic data;
- Efficiency: how practical is the training and generation pipeline
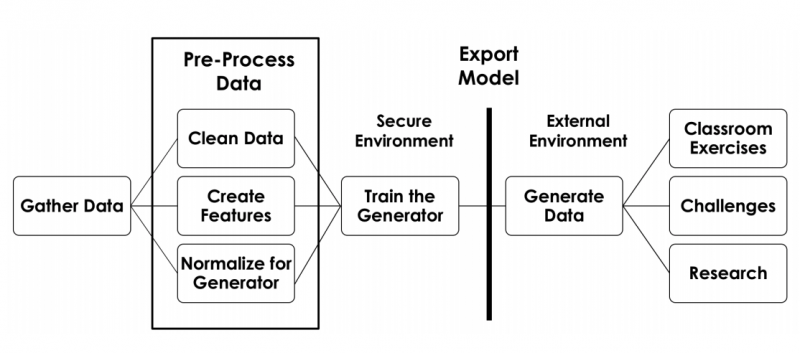
In recent publications we report our experiences generating synthetic data using a novel pipeline for generating synthetic data securely, now available as a Python package on GitHub. We demonstrate the effectiveness of HealthGAN in producing high quality synthetic data for three research studies on MIMIC data and two research studies on comorbidites of Autism Spectrum Disorder.
Links
- synthetic_data: a Python module that enables the generation of synthetic data from real data. synthetic_data enables generation of data which can be distributed easily without revealing private information.
- Talk: Privacy-preserving Synthetic Health Data Generation and Evaluation Andrew Yale (22 Apr 2020).
- Saloni Dash, Ritik Dutta, Isabelle Guyon, Adrien Pavao, Andrew Yale, and Kristin P Bennett. "Synthetic event time series health data generation." arXiv preprint arXiv:1911.06411, 2019.
- Andrew Yale, Saloni Dash, Karan Bhanot, Isabelle Guyon, John S. Erickson, and Kristin P. Bennett. "Synthesizing quality open data assets from private health research studies." To appear in Proceedings of BIS 2020: 23rd International Conference on Business Information Systems, Colorado Springs, CO, USA, June 8–10, 2020.
- Andrew Yale, Saloni Dash, Ritik Dutta, Isabelle Guyon, Adrien Pavao, and Kristin Bennett. "Privacy preserving synthetic health data." European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Bruges (Belgium), 24-26 April 2019, i6doc.com publ., ISBN 978-287-587-065-0. Available from http://www.i6doc.com/en
- Andrew Yale, Saloni Dash, Ritik Dutta, Isabelle Guyon, Adrien Pavao, and Kristin P Bennett. "Assessing privacy and quality of synthetic health data." In Proceedings of the Conference on Artificial Intelligence for Data Discovery and Reuse, pages 1–4, 2019.
- Andrew Yale, Saloni Dash, Ritik Dutta, Isabelle Guyon, Adrien Pavao, and Kristin P Bennett. "Generation and evaluation of privacy preserving synthetic health data." Neurocomputing, 2020
- Saloni Dash, Andrew Yale, Isabelle Guyon and Kristin Bennett. "Medical Time-Series Data Generation using Generative Adversarial Networks." To appear in the Proceedings of AIME2020: 2020 International Conference on Artificial Intelligence in Medicine, 2020.